Ransomware-resistant backups with duplicity and AWS S3
Why you should care about ransomware attacks even for irrelevant internet-connected systems, and how to use duplicity with AWS S3 to create ransomware-resistant backups.

Ransomware and backups
Article updated: February 5th, 2022
Ransomware is changing the security scenario. Once upon a time, attackers who entered your systems could pull some data to sell it somewhere; they could deface your website for kudos; but, unless they had some compelling reason (disgruntled former employees), they probably wouldn't destroy your data and your backups.
Now they would, though. Cryptocurrencies make it very easy to ask for a ransom and never get caught. Hence, cryptolocker-like malwares are spreading. You're not safe just because why should anybody hack into my little server: if a widespread exploit is found, cybercriminals will perform a mass scan on the whole internet, exploit and implant a malware on every single vulnerable system, then ask some amount of cryptocurrency to get your data back.
So: people should revise their own threat models. And your backup strategy is likely one of the first things you should revise. It's quite likely it was designed for a failure scenario (hardware failure, accidental deletion), not for an attack scenario. But even half-serious cybercriminals, once they get access to your server, will delete all backup sets they can access, so that their encrypt-your-data-and-ask-for-money threat actually works.
Once upon a time
You had backups on a tape library. A tape drive is usually append-only, and the backup is handled through a dedicated system so it was hard (if possible at all) and clunky to wipe an older backup from a compromised system. And tapes would get physically rotated - getting hold of an old tape was not feasible for a remote attacker, so at least you got an older backup which was safe.
Then approaches like bacula were common - the bacula server (where the backups are saved) would contact the bacula clients (systems to be backed up) and asked for data to be saved. The bacula server deleted old data using its own schedule, there was no way for the bacula client to tell it "wipe everything" so again, barring any bacula server exploit, bacula server data held backups safe.
More recently, cloud approaches like rsync.net leverage ZFS snapshots to make remote data immutable - they can be removed only according to your retention schedule (details). BorgBase works in a similar way and has a good writeup about backup strategies. Such providers usually work well since it's their very job, and should be considered when choosing a backup strategy. I won't recommend any of them since it's outside the scope of this post (and I haven't tested all of them!); just rememeber to consider restore costs and speed as well as backup costs for those providers since, just like raw cold-storage providers (e.g. AWS Glacier, Backblaze B2, et cetera) they sometimes tend to ask for a plus whenever you need to download your data - at the moment of this writing BorgBase doesn't seem to charge for download, though, but they reserve the right to terminate your account if they see excessive usage, so the topic is definitely of concern for backup providers.
But, many modern backup systems don't take the ransomware scenario into account, since the backup software needs full access to a local or remote filesystem. Some actually try: restic offers rest-server, which has an append-only option to prevent malicious deletion of the server's content. But you need an additional system just to host the server.
The cloud to the rescue
So, here we'll see how to use the good old duplicity backup software to perform backups to AWS S3 in a ransomware-resistant way. You can use any cloud storage that supports properly fine-grained permissions (see later) and is supported by duplicity.
For the sake of this article, I suppose you've got access to two distinct machines: your workstation and your server, and you'd like to have your server backed up. You could actually employ a single machine to perform all the steps, but you'll need to make sure that your master access to AWS S3 is never compromised, otherwise say goodbye to your ransomware resistance.
So, make yourself a favour and use two separate machines.
Create your S3 bucket and credentials
Those steps must be taken from your workstation
These examples don't leverage the aws cli to prevent accidents with API key leakeges; if you use the AWS S3 Console, and you've properly configured 2FA for your account, it's less likely you can be attacked that way.
Create the bucket
Enter the AWS Console, choose the S3 service, create a bucket (we'll call it sample-duplicity-backup for the sake of this article) in your preferred region (I will use eu-central-1) ; and use these settings:
Disable ACLs
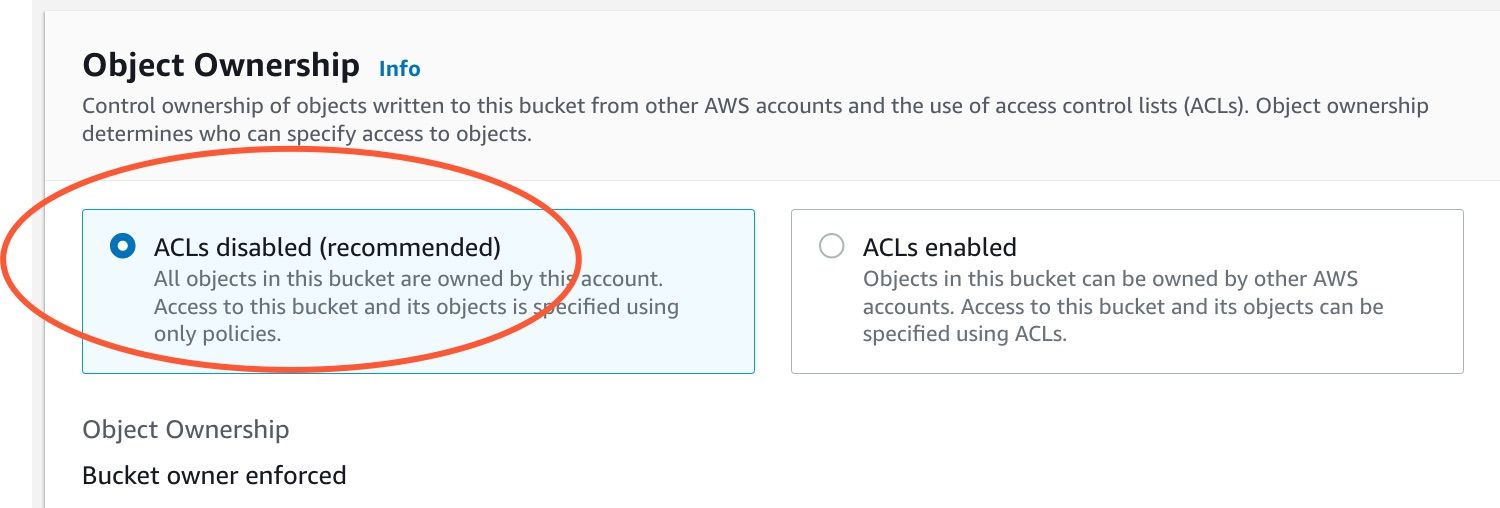
Block public access
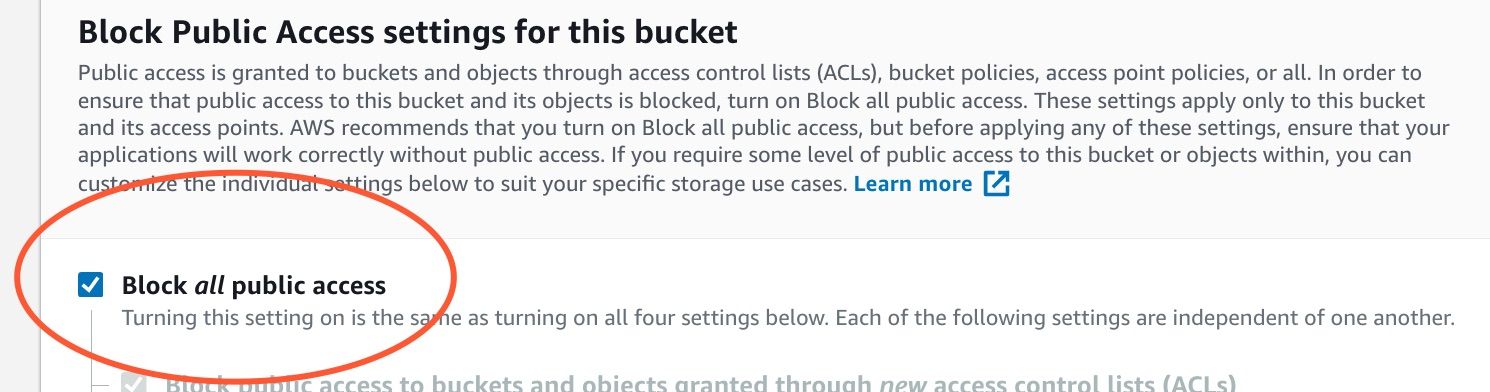
Enable bucket versioning
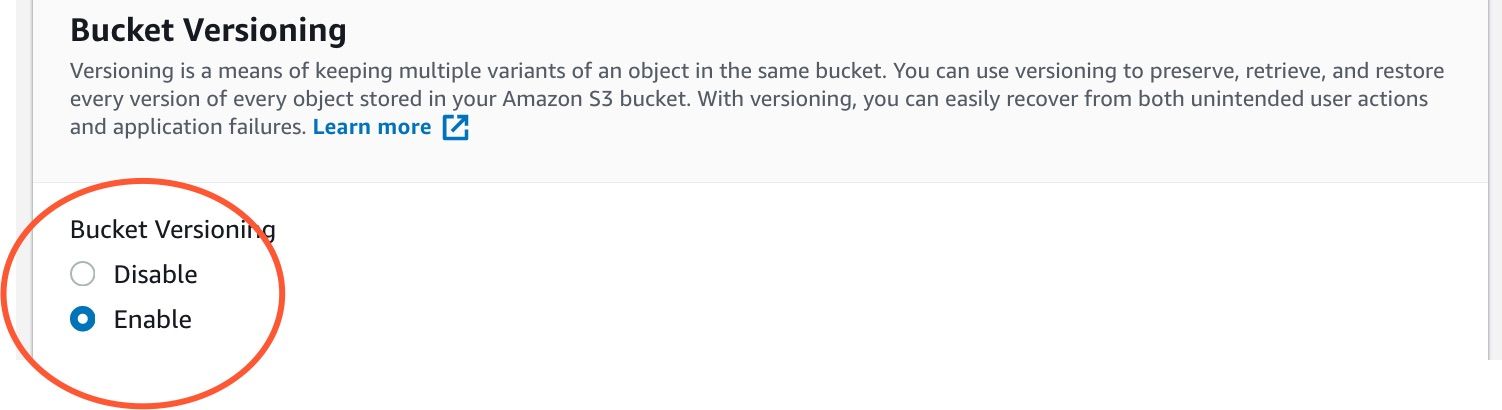
Enable object lock
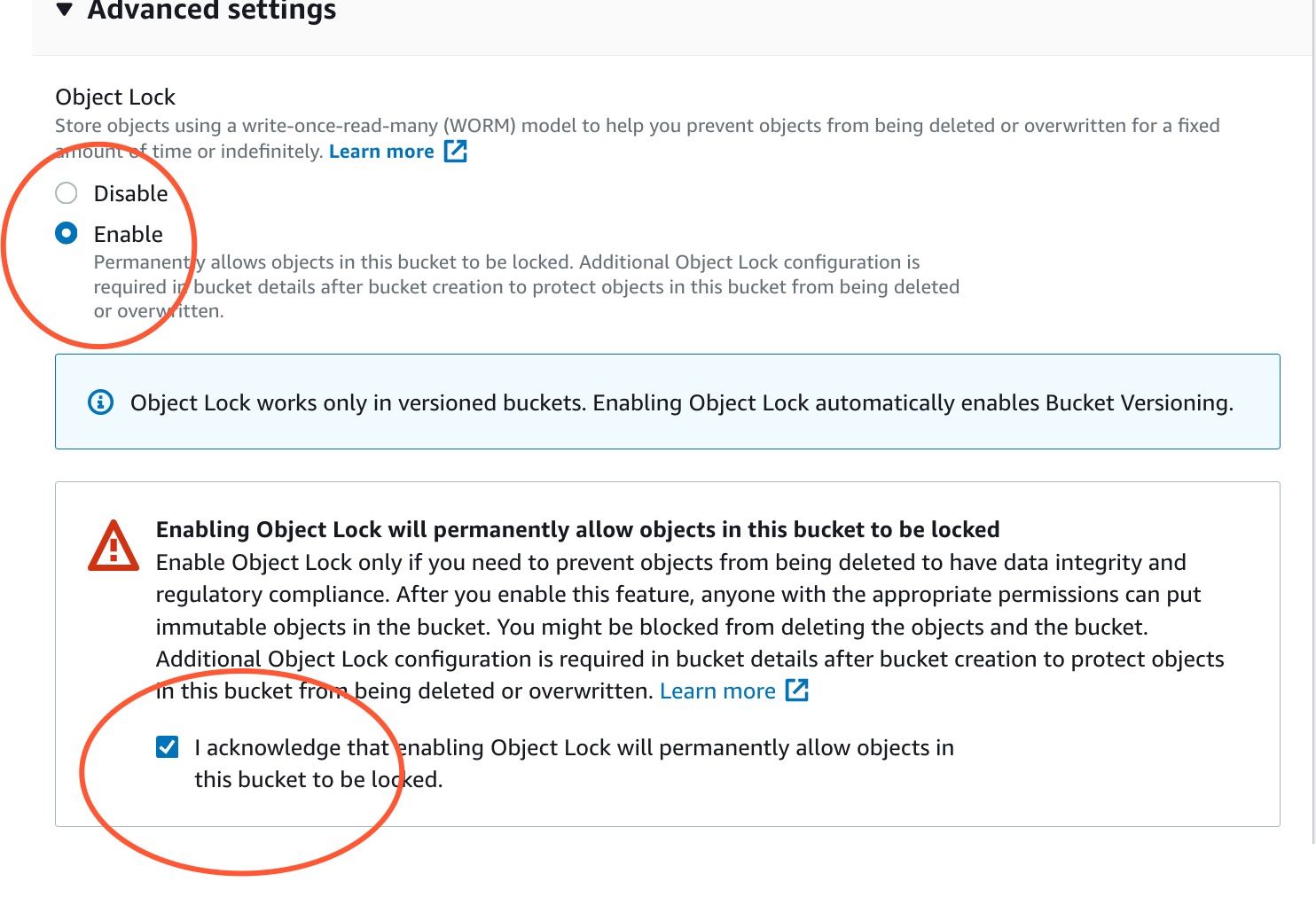
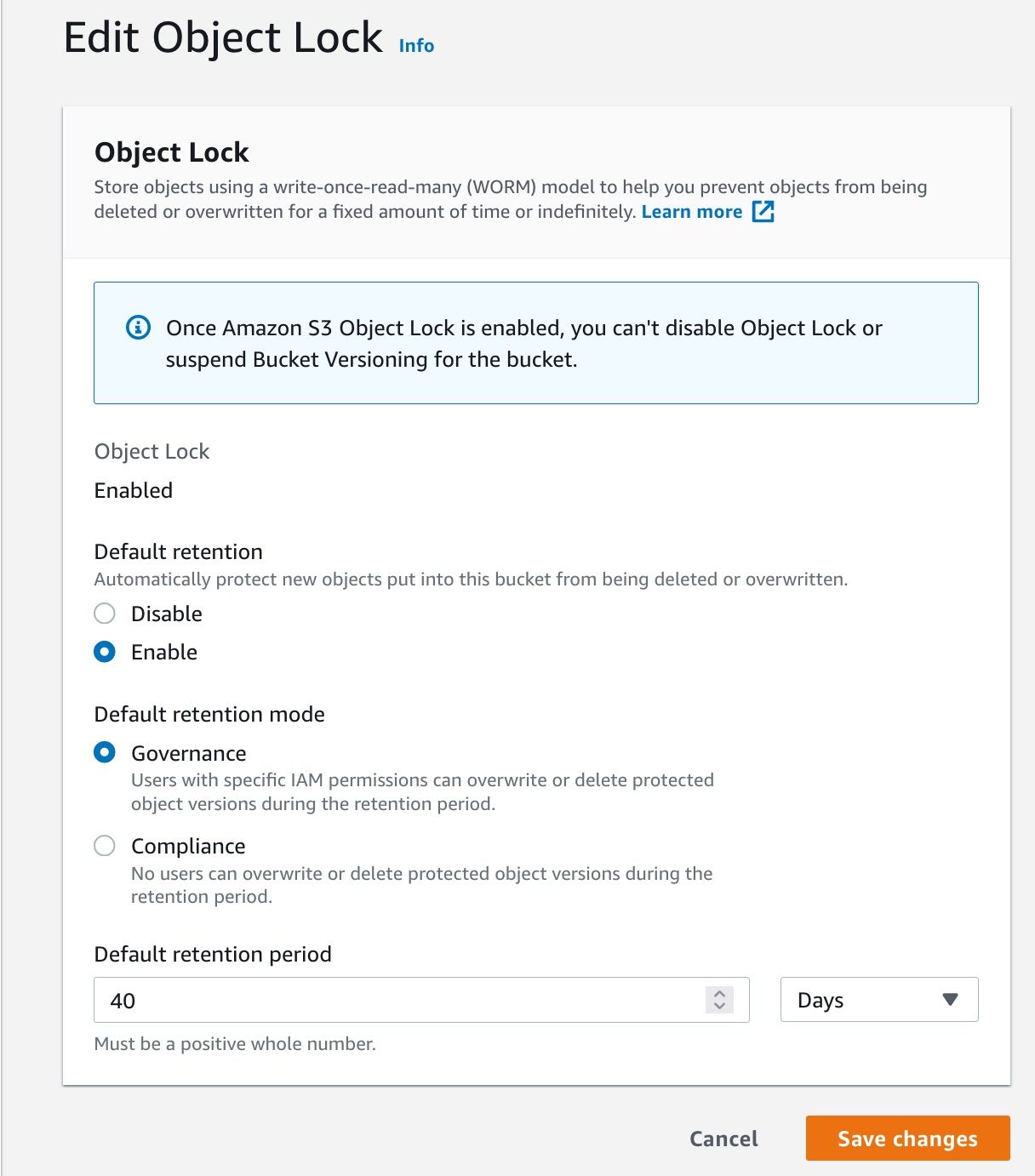
Configure object lock
Then, select the bucket you just created, go to Properties, choose Object Lock, and enable Default Retention. For the purpose we have, Governance mode is OK; choose a 40 days default retention period, and save your changes.
Create a IAM user
Now you need to create a suitable IAM user to be used with duplicity. Let's call this sample-duplicity-user; it should only have programmatic access, and you should attach only this policy to such user:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject",
"s3:ListBucketMultipartUploads",
"s3:AbortMultipartUpload",
"s3:ListBucket",
"s3:ListMultipartUploadParts"
],
"Resource": [
"arn:aws:s3:::sample-duplicity-backup",
"arn:aws:s3:::sample-duplicity-backup/*"
]
}
]
}
Download the access key ID and the secret access key for such user.
Install duplicity
The following steps must be performed on the server
Duplicity may be available in your distribution, but I suggest you pick a recent version (0.8.x) in order to make sure the s3 remote backend is properly supported - check the homepage for further info. Also make sure the boto3 library and gnupg are available on your system.
As an example, for recent Ubuntu versions (tested on 20.04):
- Add the stable duplicity PPA
apt -y install duplicity python3-boto3 gnupg
Create a backup script
Put some data in /root/data for the purpose of this test.
Then, add the following snippet to a script; set the passphrase as you wish (duplicity encrypts the backups using symmetric cryptography - support for public key crypto is available but I haven't had great success with it so far), and fill in the AWS credentials you got from the previous step:
#!/bin/bash -e
export PASSPHRASE="XYZXYZXYZ"
export AWS_ACCESS_KEY_ID="XXXXXXX"
export AWS_SECRET_ACCESS_KEY="YYYYYYYYY"
/usr/bin/duplicity \
--s3-european-buckets \
--s3-use-new-style --asynchronous-upload -v 4 \
incr --full-if-older-than 30D \
/root/data \
"boto3+s3://sample-duplicity-backup/data"
This command will backup the contents of /root/data to your s3 bucket, using a
data prefix.
One detail to note: the --full-if-older 30D means: create an incremental backup
since the previous one, or create a new full backup if more than 30 days passed since our last full backup. It is essential that the number of days that we set here is smaller than the object lock days.
So, great! Now, from your workstation, you can check that your S3 bucket contains some data; check the Objects tab of your bucket, and enter the data directory:
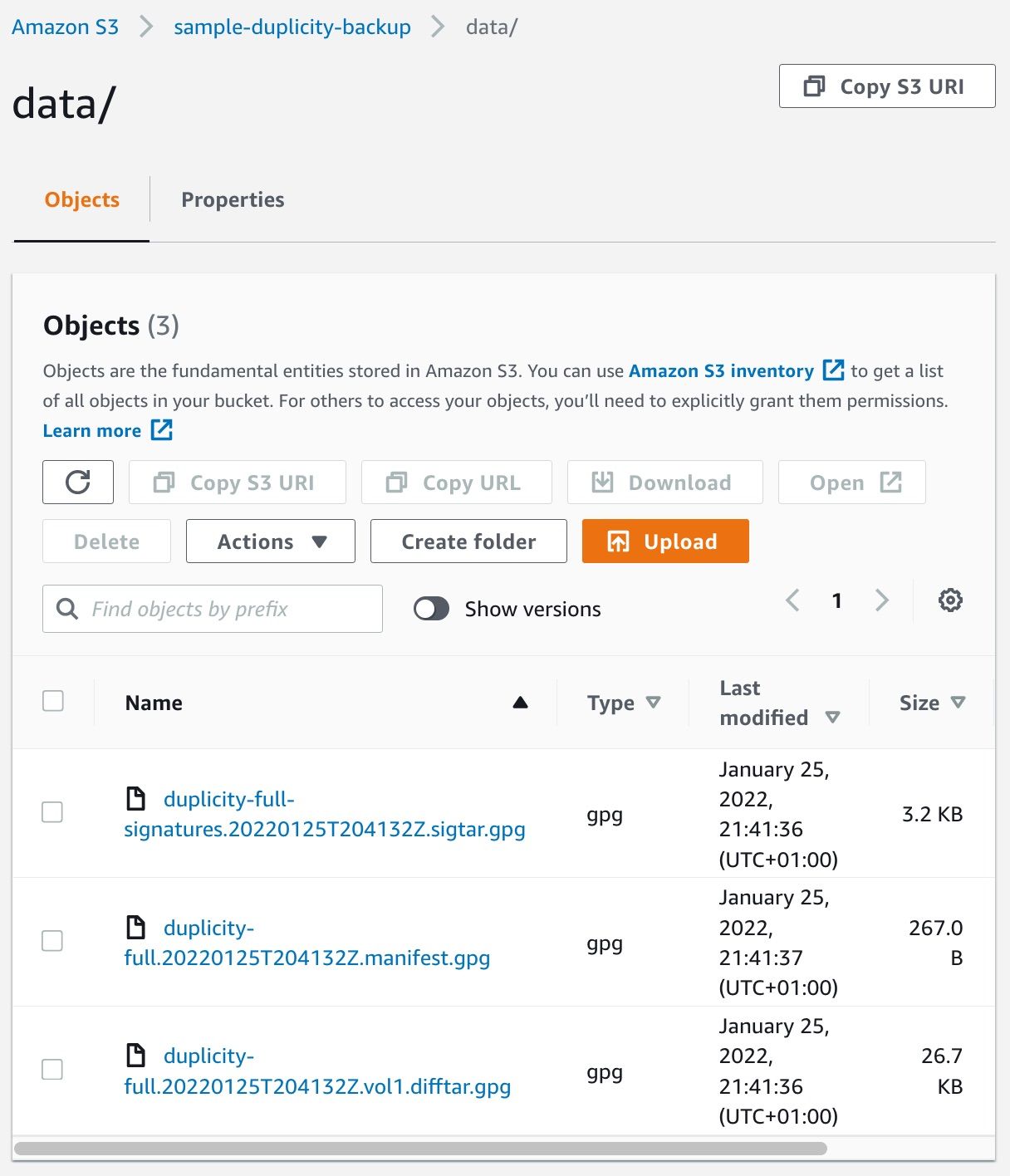
If you like, you can run the script again. You'll notice that duplicity only adds new data to the s3 bucket, it never removes or changes existing files once they have been uploaded.
Attack scenario
Now a Bad Guy exploits a vulnerability and takes total, root control of your server. He gets all your data; you can't help that, it's compromised. He even gets access to the credentials for sample-duplicity-user, and, being Bad, after deleting your data directory he tries to delete the content of your backup bucket.
For the sake of simplicity, we'll configure an aws cli account (do it either on your workstation or on your server, it doesn't really make a difference. Remember to delete such credentials afterwards) using the same sample-duplicity-user credentials and pretend you're the badguy:
aws configure --profile badguy
Now, try acting as the Bad Guy:
$ aws --profile badguy s3 ls s3://sample-duplicity-backup/data/
2022-01-25 21:41:36 3228 duplicity-full-signatures.20220125T204132Z.sigtar.gpg
2022-01-25 21:41:37 267 duplicity-full.20220125T204132Z.manifest.gpg
2022-01-25 21:41:36 27298 duplicity-full.20220125T204132Z.vol1.difftar.gpg
He can read the backup. This is expected. But can he delete the backup?
$ aws --profile badguy s3 rm s3://sample-duplicity-backup/data/duplicity-full.20220125T204132Z.manifest.gpg
delete failed: s3://sample-duplicity-backup/data/duplicity-full.20220125T204132Z.manifest.gpg An error occurred (AccessDenied) when calling the DeleteObject operation: Access Denied
The attacker cannot delete files; our object lock policy prevents that!
But, there's still one thing that the attacker could do: overwrite existing files. In fact, AWS S3 Put actions (and permissions) don't make a distinction between "add an object" or "overwrite an existing object" (and it would be quite difficult and slow to implement in a distributed storage system):
$ aws --profile badguy s3 cp temp.txt s3://sample-duplicity-backup/data/duplicity-full.20220125T204132Z.manifest.gpg
upload: ./temp.txt to s3://sample-duplicity-backup/data/duplicity-full.20220125T204132Z.manifest.gpg
Ouch! This (apparently) succeeded:
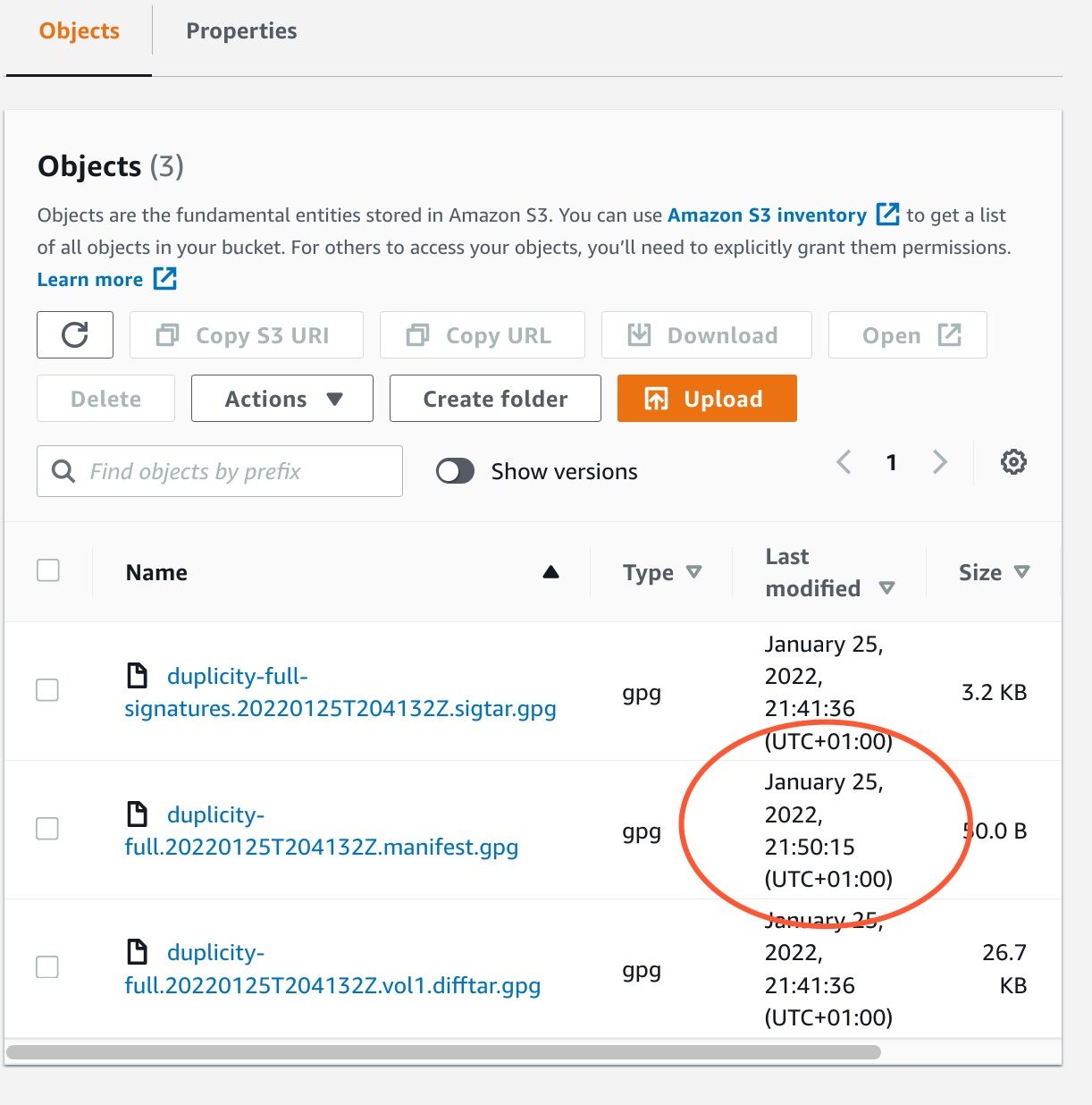
But the reality is that the original data is still there: the attacker has uploaded a new file with same name as ours, but we can still retrieve the first version; Object Lock and Bucket Versioning work together. Check the "Versions" tab for our modified file:
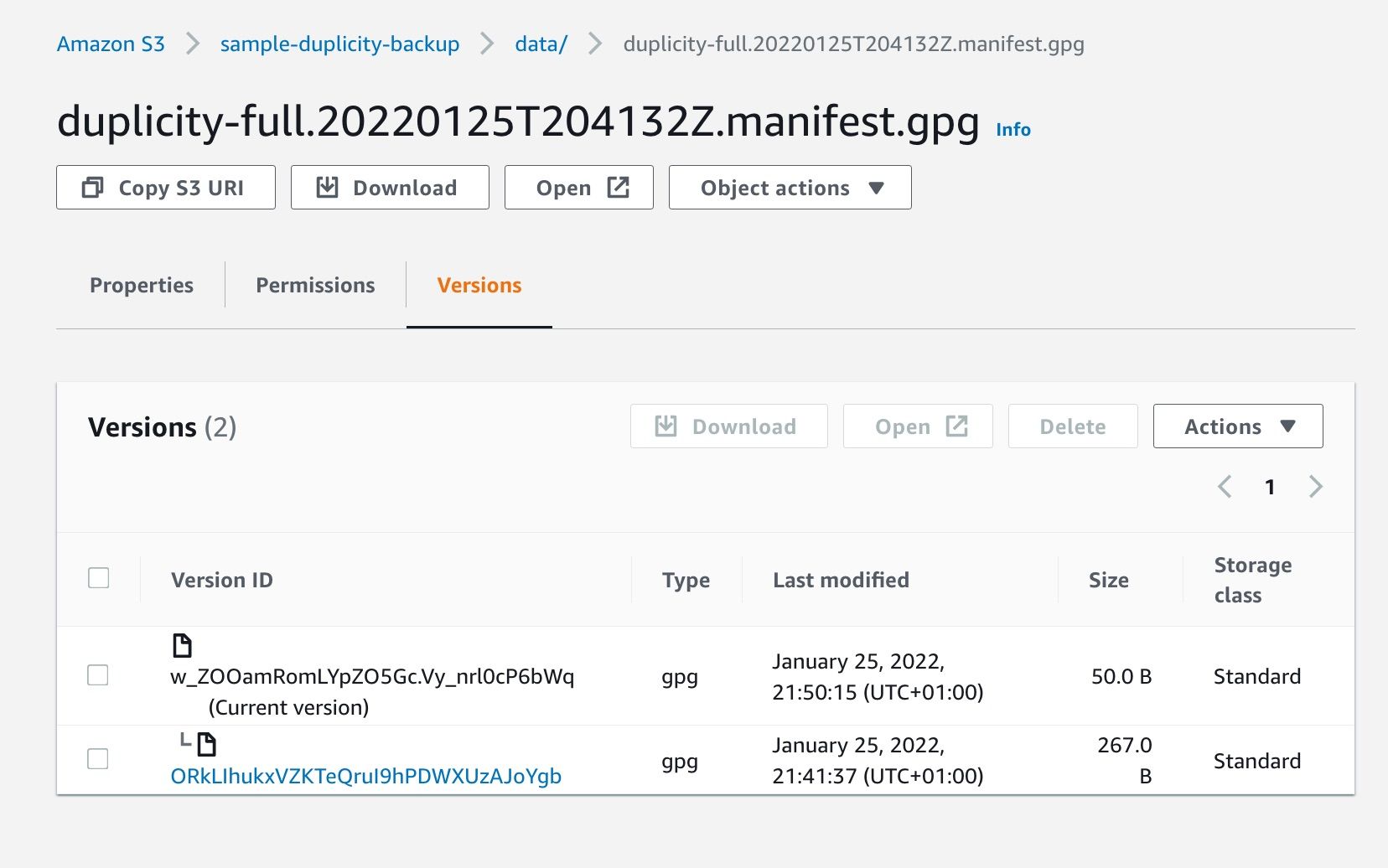
Choose the older version and download it: it's the original file! So, if you get hit by a ransomware, you can still retrieve all your original files. Accessing those in a programmatic way requires the s3:ListBucketVersions permission (check the API call as well) - we don't even have it for our backup IAM user.
Retrieving the original files
A full demonstration of how to retrieve the original files is trivial and beyond the scope of this article; but I'll leave some breadcrumbs here. With an user with the ListBucketVersions permissions, call this command:
$ aws s3api list-object-versions --bucket sample-duplicity-backup
{
"Versions": [
...
{
"ETag": "\"500e2a10137f805dba21f4bb7bf3678a\"",
"Size": 50,
"StorageClass": "STANDARD",
"Key": "data/duplicity-full.20220125T204132Z.manifest.gpg",
"VersionId": "w_ZOOamRomLYpZO5Gc.Vy_nrl0cP6bWq",
"IsLatest": true,
"LastModified": "2022-01-25T20:50:15+00:00",
"Owner": {
"ID": "132149dd72a1af36909b73ae719ccba0096cd23aa62158308ef4b9619f3b63ed"
}
},
{
"ETag": "\"2dd325e03ac11eb6edaf0e9a7b177064\"",
"Size": 267,
"StorageClass": "STANDARD",
"Key": "data/duplicity-full.20220125T204132Z.manifest.gpg",
"VersionId": "ORkLIhukxVZKTeQruI9hPDWXUzAJoYgb",
"IsLatest": false,
"LastModified": "2022-01-25T20:41:37+00:00",
"Owner": {
"ID": "132149dd72a1af36909b73ae719ccba0096cd23aa62158308ef4b9619f3b63ed"
}
},
...
]
}
Then retrieve this file in its older version:
$ aws s3api get-object --bucket sample-duplicity-backup --key data/duplicity-full.20220125T204132Z.manifest.gpg duplicity-full.20220125T204132Z.manifest.gpg --version-id "ORkLIhukxVZKTeQruI9hPDWXUzAJoYgb"
{
"AcceptRanges": "bytes",
"LastModified": "2022-01-25T20:41:37+00:00",
"ContentLength": 267,
"ETag": "\"2dd325e03ac11eb6edaf0e9a7b177064\"",
"VersionId": "ORkLIhukxVZKTeQruI9hPDWXUzAJoYgb",
"ContentType": "binary/octet-stream",
"Metadata": {}
}
$ ls *.gpg
duplicity-full.20220125T204132Z.manifest.gpg
Apply for all files where you actually need it. Actually, it's quite likely that the attacker will have noticed the bucket is versioned and object locked, so he won't waste time at overwriting all files.
Wrapping up
I hope this article can be useful from an implementation standpoint, but the most important takeaway is: always think about your threat model every time you take a decision. Reason in the terms of what an attacker could do when entering your system; security is never binary.
And, please: don't run your applications as root, but run your backup script as root, and make sure its ownership and permissions are properly set, like -rwx------ 1 root root 365 Dec 9 21:52 duplicity_run. It's great to have a ransomware resistant backup, but you shouldn't make things too easy for an attacker!
An exercise
An attacker enters your server, but he realizes you're using object lock and bucket versioning. But he really wants to find a way to get some money from you, since he knows you're full of XMR in your wallets. Hypothesize how could he proceed, then go on and think about what you could do to prevent damages to your system and to your backups.
To my readers: since this is sort of security-related and a topic with a potentially high impact, please let me know if got anything wrong. Contact me by commenting or directly via e-mail.
Updates & footnotes
I received a decent amount of feedback about this article. I think this means that the topic is interesting at least interesting. Thanks to the HN crowd as usual for commenting.
Even though this should be a basic functionality, it seems incredibly hard to get done right unless you have a dedicated SRE team.
So, some additional, interesting points (I meant for some of those were covered in my 'exercise' paragraph, but I'm now jotting them down):
- You should remember to periodically verify your backups, usually by restoring them - this is true in general for backups, not just for ransomware resistant ones. For the ransomware situation, you must make sure to verify your backups more often than their expiration period on S3, otherwise an attacker could a) tamper with your backup script making it ineffective and b) wait for governance lock time to expire, and hope old data gets deleted by some schedule (they can't actually delete data because they don't have such right). So, make sure you verify backups before deleting old data.
- Use a proper account for backups; the risk, sometimes, is that backups get deleted/attacked because of accidental exposure from the backup account. I recommend using a separate AWS account with highly restricted IAM users for backup scenario; you can even replicate buckets between accounts
- Somebody stealing your S3 credentials could just use them for their own purpose and save arbitrary data there, with you incurring the costs. But you don't want an hard limit before s3 stops working (I'm not even sure it's possible), otherwise you'll enable the attack to escalate into a ransomware. So I recommend setting a proper budget alert for your AWS account and maybe an alert for excessive S3 data usage
- Some people report that duplicity, when used with a great amount of data, can start using an excessive amount of memory and ultimately gets killed because the server runs out of ram. I can't confirm or deny this either, just make sure, again, to monitor your backup job - so you get errors if it fails - and to periodically verify them.
- If you've got a lot of data and not a lot of bandwidth - hence the initial backup may take you a lot time - make sure you pick a good, reliable provider that won't be gone in one or two years. That's the reason I used S3: I suppose it will be still there in 10 or 20 years.

